



将 DISTINCT 关键字添加到 SELECT 查询后,查询将仅返回指定列列表的唯一值,以便从结果集中删除重复的行。由于 DISTINCT 对 SELECT 的列列表中的所有字段进行操作,因此不能将其应用于一组字段中的单个字段。话虽这么说,但有多种方法可以从一列中删除重复的值,而忽略其他列。今天,我们将在这里介绍其中的几种。
测试数据
为了测试我们的查询,我们需要一个包含重复数据的表。为此,我在 Sakila 示例数据库的 customer 表中添加了一些额外的电子邮箱。这是 Navicat Premium的网格视图的屏幕截图,显示了一个拥有 2 个关联电子邮箱的客户:
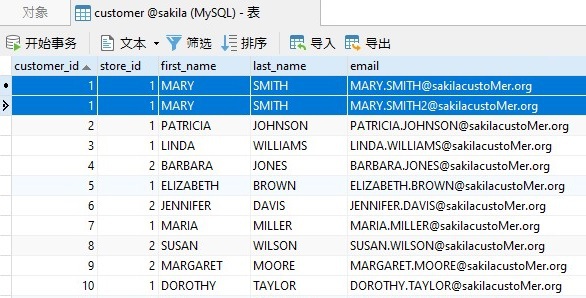
如果现在将 DISTINCT 子句添加到其字段列表包含其他列的查询中,则 DISTINCT 不起作用,因为整行是唯一的:
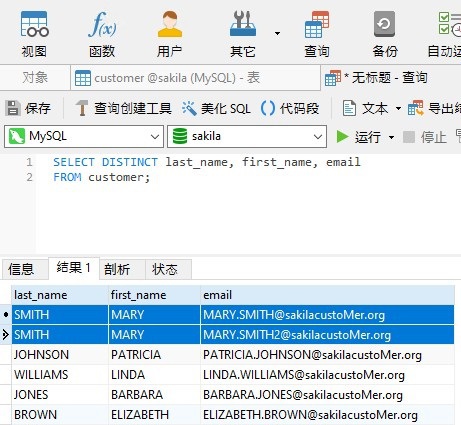
那么,怎样才有用呢?让我们找出答案!
使用 GROUP BY
GROUP BY 子句根据一个或多个字段对结果进行分组,将聚合函数应用于特定的数据子集。当与 MIN 或 MAX 之类的功能结合使用时,GROUP BY 可以将一个字段限制为相对于另一个字段的第一个或最后一个实例。
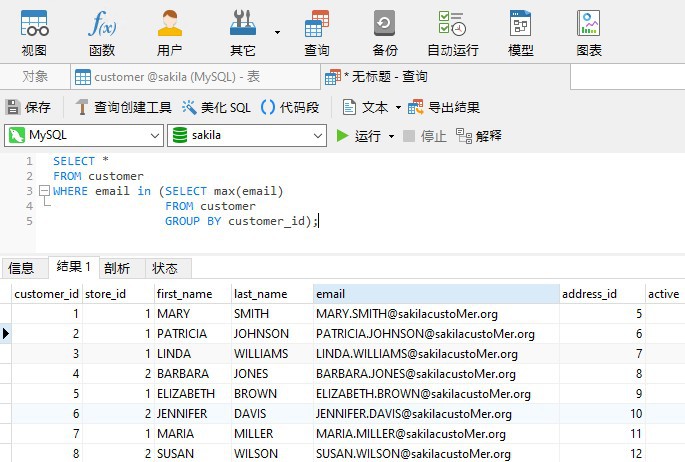
因此,如果我们希望将每个客户的电子邮箱限制为一个,则可以包含一个子查询,该查询按 customer_id 分组电子邮箱。然后,我们可以通过将 email 列与子查询返回的唯一列相结合来选择其他列:
使用视窗函数
另一个(稍微更高级的解决方案)是使用窗口函数。因为他们对一组与当前行相关的表行进行计算,所以被命名窗口函数。与常规聚合函数不同,窗口函数不会导致行被分组为单个输出行,从而使行保留其各自的标识。
ROW_NUMBER() 是一个窗口函数,为结果集分区中的每一行分配一个连续的整数,每个分区的第一行从 1 开始。对于客户的电子邮箱,第一个电子邮箱返回 1,第二个电子邮箱返回 2,依此类推。然后,我们可以使用该值(以下称为“rn”)选择每个客户的第一个电子邮箱。
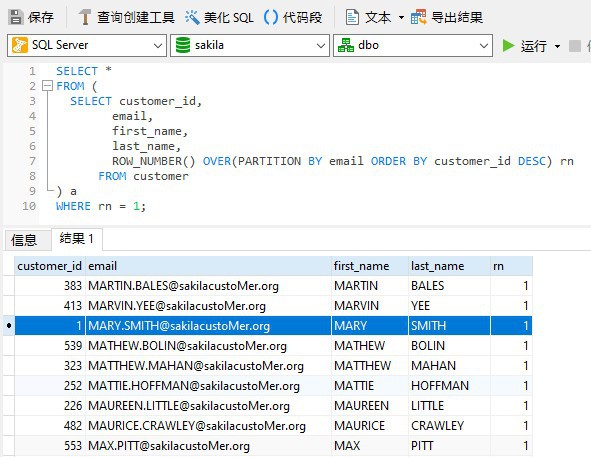
请注意,并不是所有的关系数据库都支持窗口函数。SQL Server 确实支持,而 MySQL 在版本 8 中引入了它们。
总结
在今天的文章中,我们学习了如何使用 GROUP BY 和窗口函数从一组字段中的单个字段中删除重复项。毫无疑问,还有很多其他方法可以实现相同的最终目标,但是这两种可靠的技术应该更切合你的需要。
如果你对 Navicat Premium 感兴趣,可以免费试用 14 天!








