



GROUP BY 和 ORDER BY 都是具有相似功能的子句(或语句),即是对查询结果进行排序。但是,它们的目的截然不同。实际上差异非常之大,以至于它们可以单独使用或一起使用。如果你不确定要使用哪个,事情能会变得有点冒险。在今天的文章中,我们将学习这两个子句的功能以及如何将它们一起使用以最终控制查询输出。为此,我们将使用Navicat Premium 和 Sakila 示例数据库。
GROUP BY 和 ORDER BY 的解释
ORDER BY 子句的目的是按一列或多列对查询结果进行排序。同时,GROUP BY 子句用于借助诸如 COUNT()、AVG()、MIN() 和 MAX() 之类的聚合函数将数据分组。它的工作方式是,如果特定的列在不同的行中具有相同的值,它会将这些行合并为一组。
让我们看一下每个子句的示例。
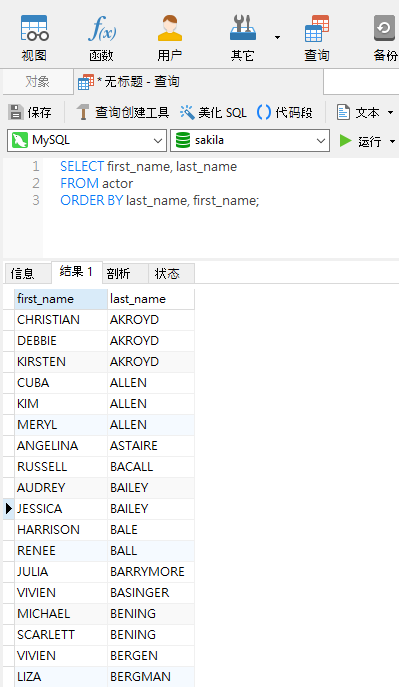
以下的查询显示表 actor 中所有演员的名字(first_name)和姓氏(last_name),并先按姓氏排序,其后再按名字排序:
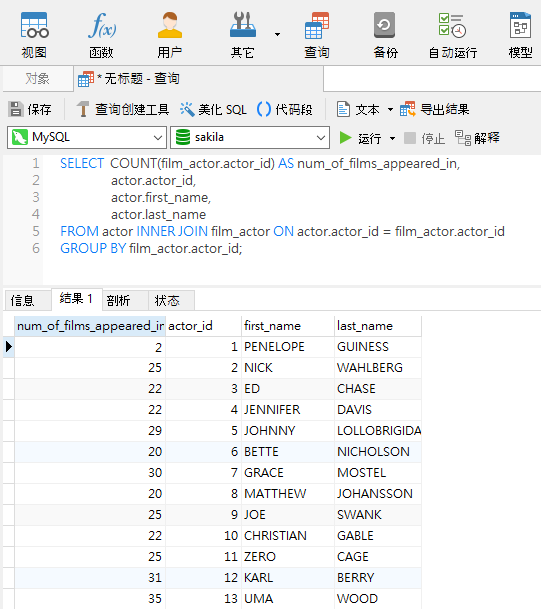
现在,以下是另一个查询,按演员编号分组,得到他们出演的电影数量:
一起使用 GROUP BY 和 ORDER BY
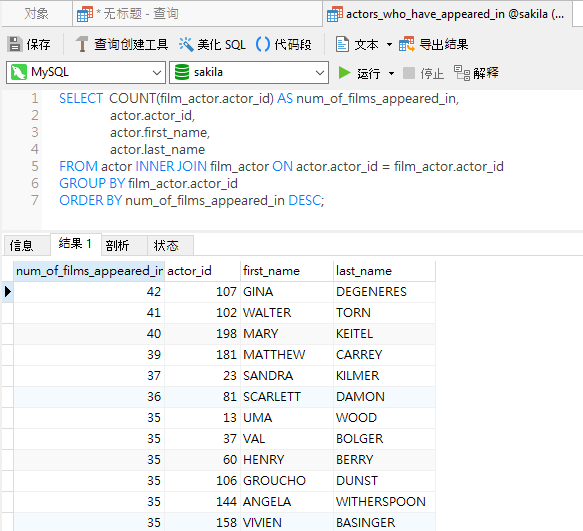
注意,在前面的查询中,记录由 actor_id 字段排序,这是对结果进行分组的依据。如果我们想使用不同的字段(即非分组字段)对结果进行排序,则必须添加 ORDER BY 子句。以下是相同的查询,但按每个演员出演的电影数量从多到少排列:
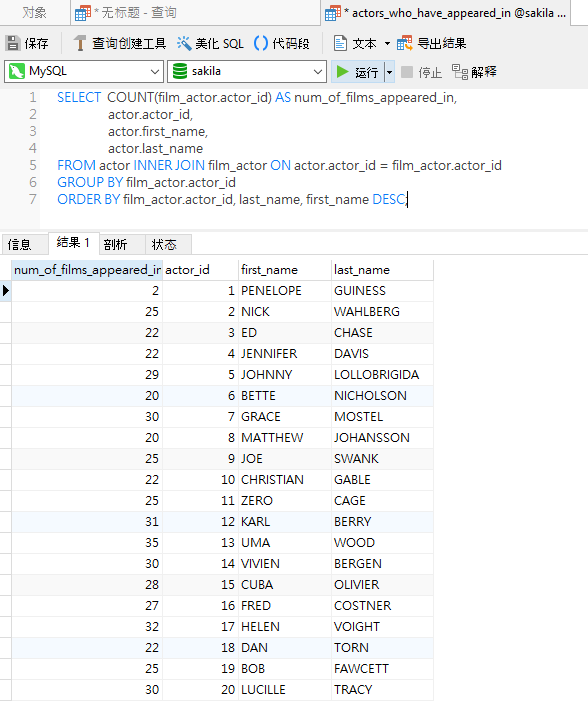
请注意,一旦包含 ORDER BY 子句,默认的组排序就会丢失。如果你想保留它,可以将分组的列添加到 ORDER BY 字段列表中:
注意事项
在组合 GROUP BY 和 ORDER BY 子句时,请记住 SELECT 语句中放置子句的位置是很重要:
- GROUP BY 子句放在 WHERE 子句的后面。
- GROUP BY 子句放在 ORDER BY 子句的前面。
GROUP BY 是在 ORDER BY 语句之前,因为后者对查询的最终结果进行操作。
额外部分:HAVING 子句
你可以使用 HAVING 子句进一步筛选分组的数据。HAVING 子句与 WHERE 子句类似,但它是对行组而不是单个行进行操作。为了说明 HAVING 子句是如何工作,我们可以使用它来将结果限制为出演过十部电影的演员:
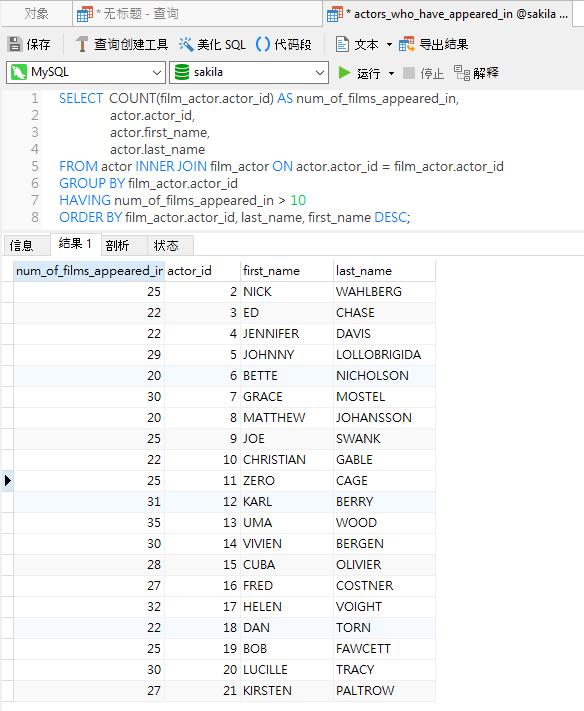
Navicat 的 SQL编辑器具有语法高亮显示、用于控制流/DDL/法语句的可重用代码段以及代码补全功能,显著地方便了查询编写。它的建议抱括模式、表、列、存储过程和函数的所有内容。以下是 HAVING 关键字:
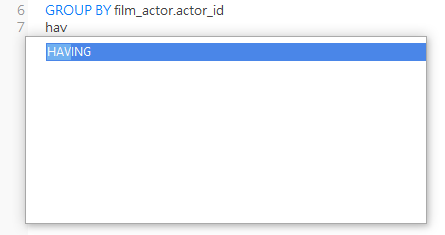
HAVING 子句应放在 GROUP BY 子句的后面,ORDER BY 子句的前面。
总结
在今天的文章中,我们了解了这两个子句的功能,以及如何在 Navicat Premium 一起使用它们对查询输出进行最终控制。
如果你对 Navicat Premium 感兴趣,可以免费试用 14 天!
Rob Gravelle 居住在加拿大渥太华,是一名有 20 多年经验的 IT 专家。过往,Rob 曾为与情报有关的组织(如加拿大边境服务局和各种商业组织)构建系统。如果你想雇用 Rob,可以发送电子邮件至 rgconsulting(AT)robgravelle(DOT)com。在业余时间,Rob 是一名出色的吉他演奏家,并发行了几张 CD。








